Usero Journal
Do AI Models Recommend the Same Feedback Tool? I Ran 577 Tests
As expected, AI never gives the same answer twice. I ran it 577 times to find what stays fixed.
There is a thread that has been making the rounds in founder circles. A founder noticed that roughly half his signups traced back to ChatGPT recommending one of his comparison blog posts. The takeaway everyone drew was hopeful: write the right content, and the models will send you customers for free.
Anyone who has used these models knows they do not give the identical answer twice. That part is not interesting. What I wanted to know is the part nobody had measured: how far does the spread actually go, and is anything underneath it stable enough to plan around?
So I took a set of product-recommendation questions in one category I know well, feedback tools, and I asked them over and over. Same prompts, same models, same settings. 577 asks in total. The interesting result was not that the answers moved, of course they moved. It was the magnitude of the move, the stable defaults sitting underneath it, and the one category every model left empty.
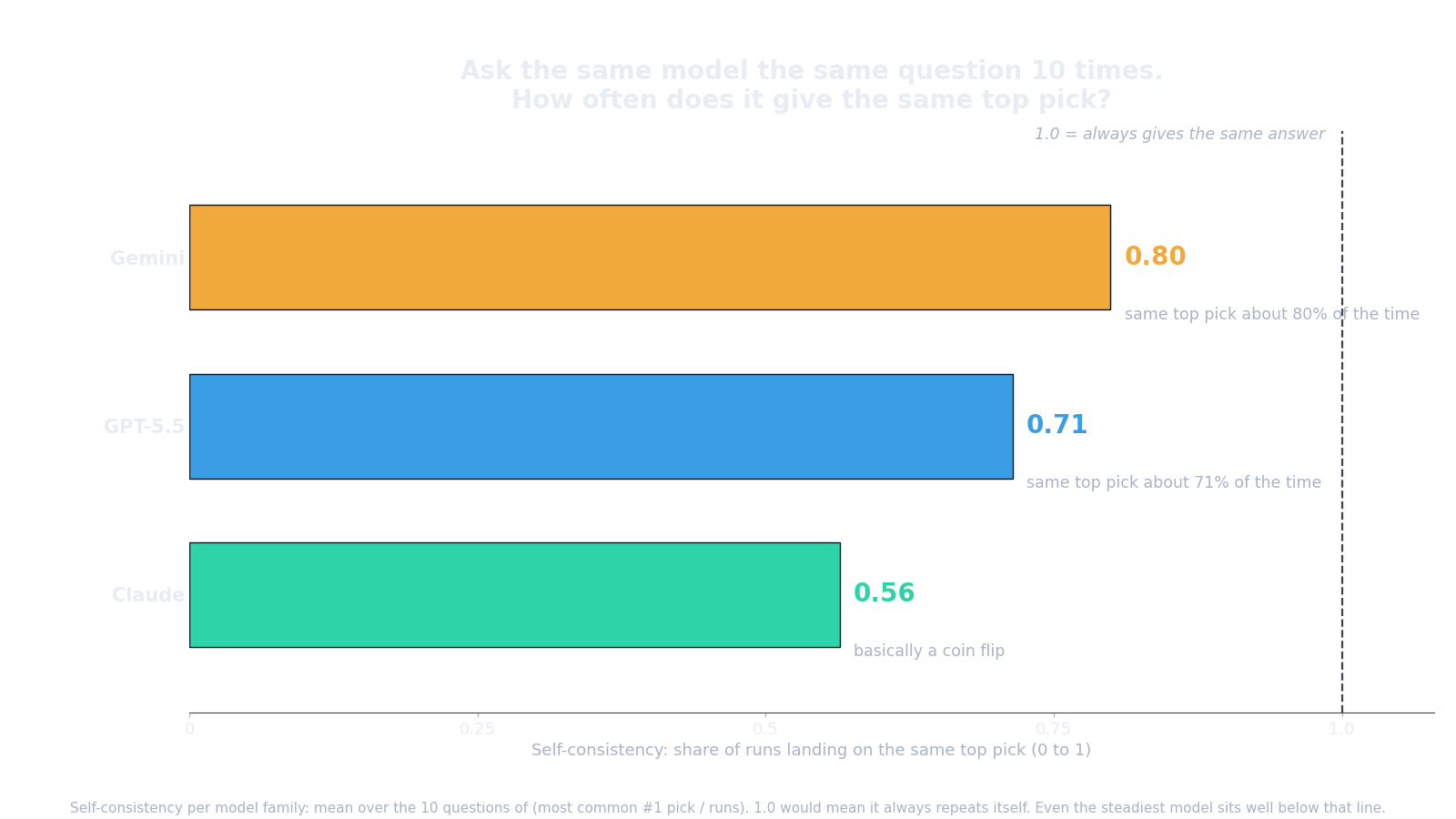
Everyone knows there is some randomness in a model’s output. The number worth having is the size of it. I asked each model each question 20 times. Gemini repeated its own single most common pick 80% of the time, GPT-5.5 71%, Claude just 56%. So even the steadiest one swaps its top pick roughly one run in five, and the flakiest, Claude, close to one run in two. Often it is naming a different product, not the same one reworded. There is no stable ranking to game.
Yes, before anyone says it: this is sampling at the default temperature, not a bug, and no, you cannot make this go away by setting temperature to zero in your own testing. Default is exactly what a real person gets when they open ChatGPT and ask.
That changes what you can plan around. There is no single “AI answer” to win. The answers move every time you ask. So the useful question becomes: given that they wobble, what moves them? That is what the rest of this is about, and the most actionable piece comes first.
Here are the ten questions I asked, the kind a real founder would type:
Comparison and alternatives
- Best Canny alternative for a startup?
- Canny vs Productboard vs Featurebase, which should I pick?
- Cheaper alternative to Productboard for a small team?
Picking a tool
- What tool should a startup use to collect user feedback?
- How do early-stage SaaS teams manage feature requests and bug reports?
Ships code from feedback (the wedge)
- Is there a feedback tool that turns user feedback into a GitHub pull request?
- What tool automatically ships code fixes from bug reports?
- Feedback tool for engineering-led teams who want fixes shipped, not just tracked?
- Feedback tool for AI-native founders who’d rather write code than triage a board?
Open source
- Open-source-friendly feedback widget that integrates with GitHub Issues?
The single most useful thing: the cited-domain to-do list
When a model searches the live web before answering, it cites the pages it read. Collect those citations across hundreds of grounded answers and you get a literal map of where AI recommendations come from.
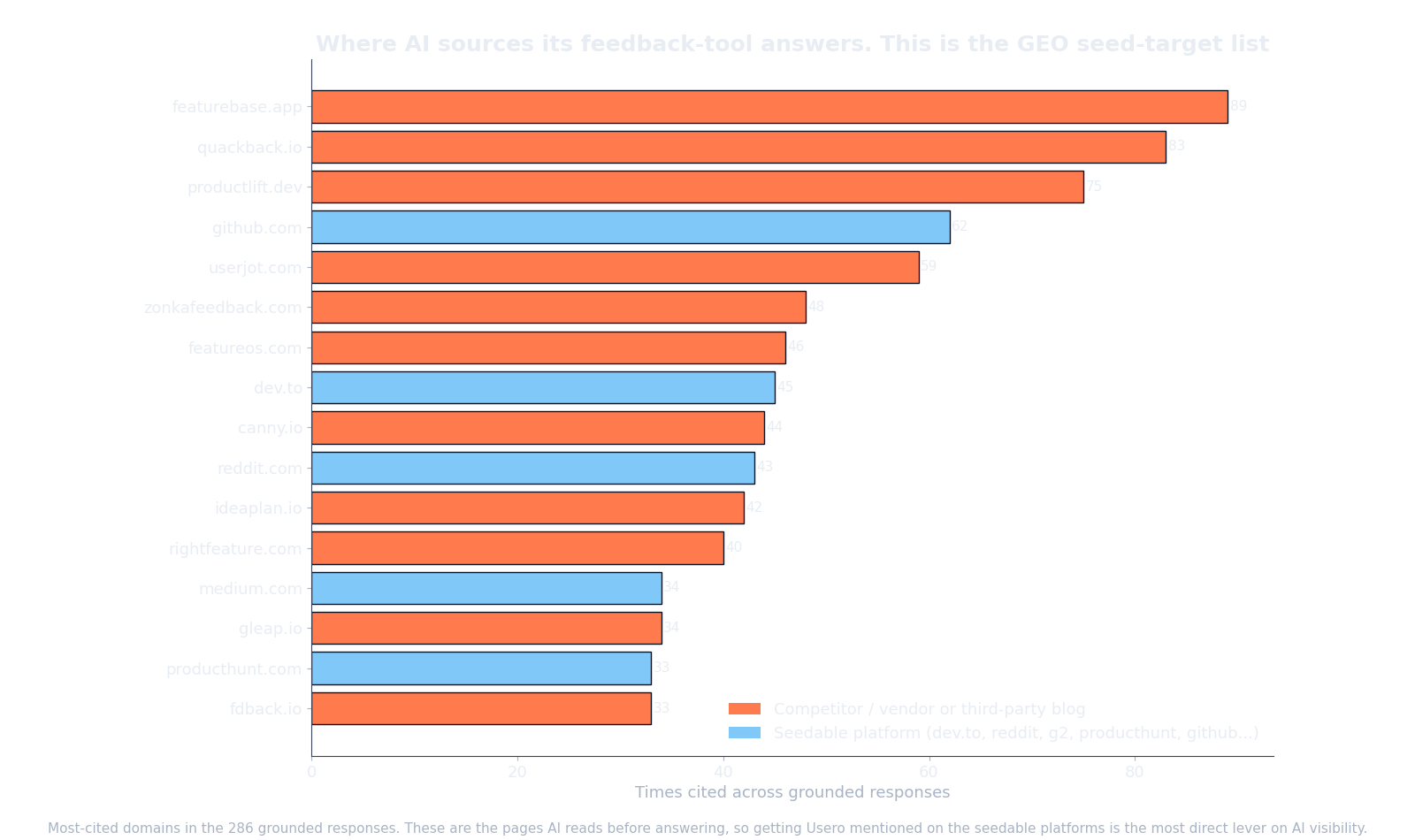
The grounded models did not reach for the big review platforms first. The most-cited domains were small competitor blogs and listicles: featurebase.app, quackback.io, productlift.dev, userjot.com. The model builds its recommendation out of whatever specific pages rank for the query, not out of brand fame.
That makes the list a to-do list. The seedable surfaces in there, the ones you can actually publish to or get listed on, were dev.to (45 citations), reddit.com (43), medium.com (34), producthunt.com (33), and github.com itself (62). Getting into a credible “best feedback tools” roundup on one of those, or onto a comparison page that ranks, is what moves your grounded number. Not a press release. Not a louder homepage. If you do one thing with this post, go find the equivalent list for your own category and get onto those pages.
The method
The ten questions are the list above, from broad comparison terms down to the precise “ships code from feedback” wedge question that never names a product.
I asked each question to three current models: GPT-5.5, Gemini 3.1 Pro, and Claude Sonnet 4.6. Each in two modes. Recall, where it answers from training with no web access, so you see what it remembers. And grounded, where it searches the live web and cites its sources, so you see what it looks up. 10 runs per question per lane, which is how you get to 577 asks. I logged every answer, every tool named, every domain cited.
The three models start from different defaults
The instability is real, but there is structure under it. Each model leans a different way. Same question, three different starting priors.
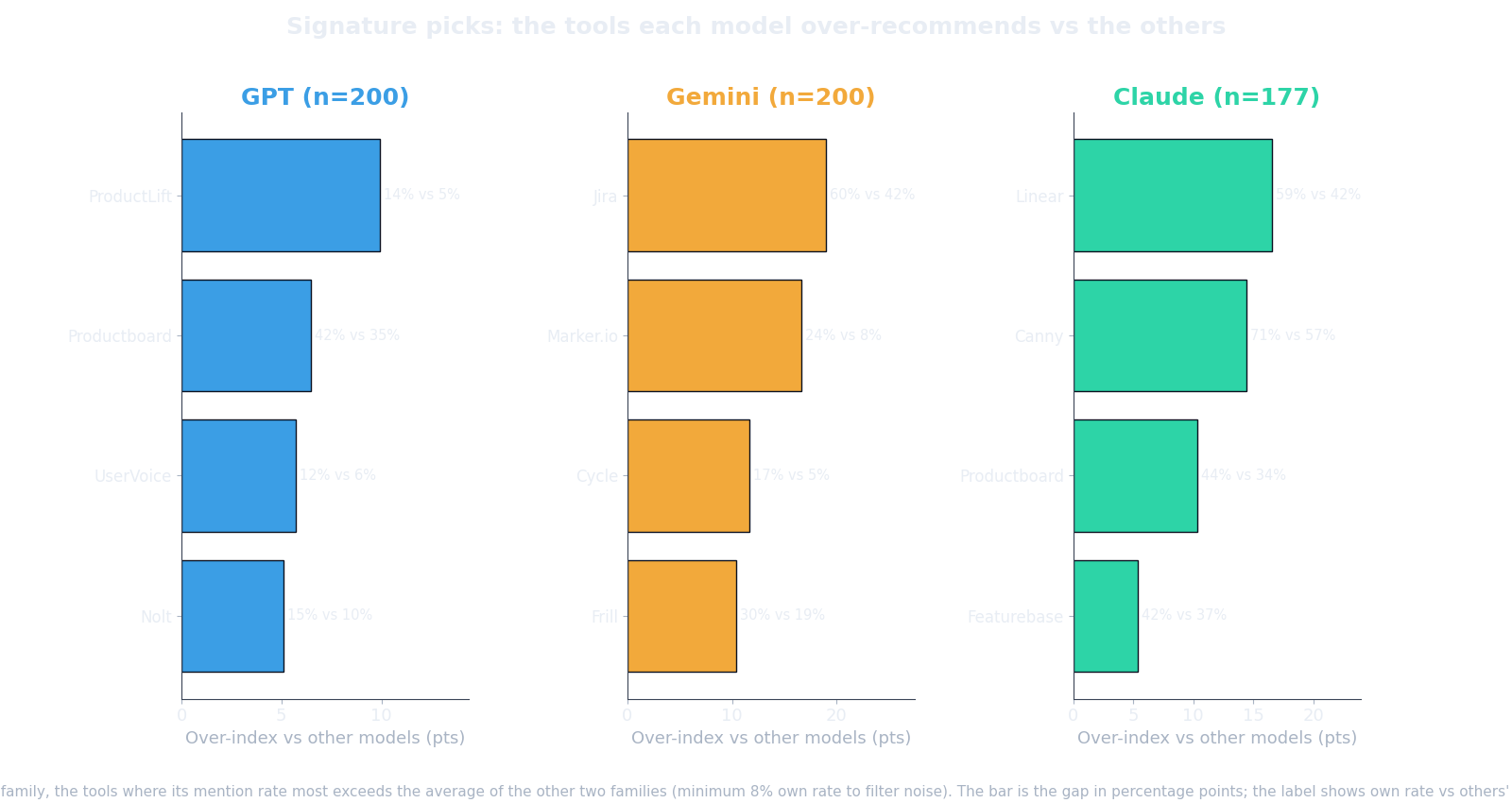
- Gemini defaults to issue trackers. It names Jira in 61% of its answers versus 42% for the other two, a 19 point lean. Some issue tracker (GitHub, Jira, Linear, Notion) shows up in 95% of everything Gemini says. Its default reading of “where does feedback go” is a tooling-and-tickets question.
- Claude pulls from the widest surface. It over-indexes on Canny and Linear, and when it searches it cites 637 distinct domains across its grounded answers, versus 212 for GPT and just 126 for Gemini. It reaches further into the long tail.
- GPT-5.5 is the most concentrated. Fewest tools named per answer, most likely to settle on a small familiar set.
These gaps (Jira +19, Linear +17, Marker.io +17) sit well outside the per-question noise, so trust them. Each model carries its own defaults, and those defaults reward different things. Gemini rewards being legible as a tool in a workflow. Claude rewards being findable across a wide surface of pages. GPT rewards being one of the few names that come to mind first.
What it remembers is not what it looks up
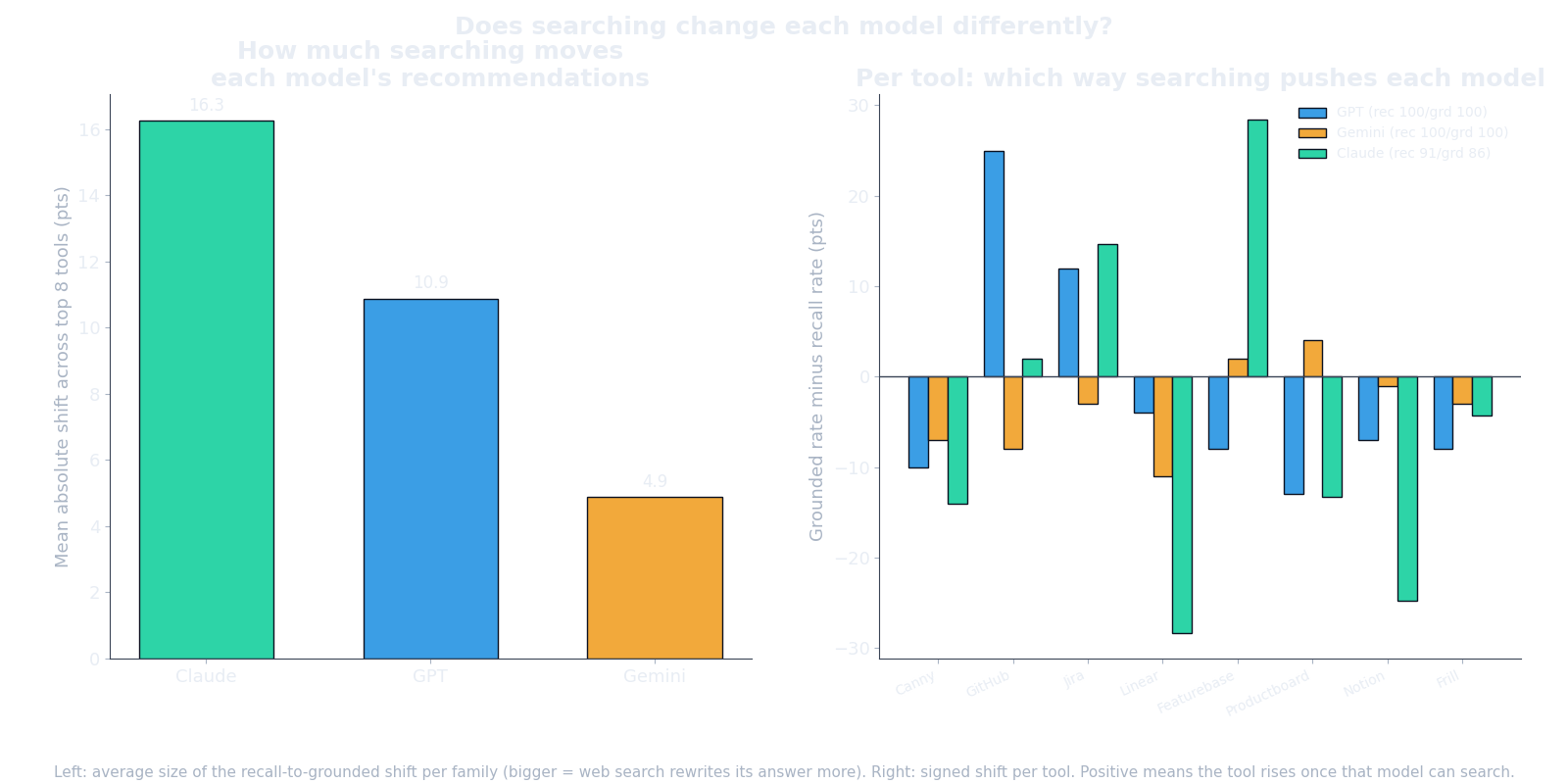
Recall and grounded name different tools. Some products sit heavy in training data and get name-dropped from memory, then slip when the model actually searches. Others barely register from memory and only surface once it reads the live web.
The size of that swing depends on the model. When Claude switches from memory to search, its top picks move an average of 16 points. GPT moves 11. Gemini barely flinches at 5. Getting cited on the live web is a lever that works hard on Claude, moderately on GPT, and almost not at all on Gemini, which mostly recommends what it already believed.
If you are a newer product, you have no memory position at all. You do not get remembered. So the grounded path is the only lever you have, and it pays off most on the models that let search change their mind. The cited-domain list is the lever. Claude and GPT are where it moves the needle.
There is an empty category sitting right there
I asked a question that describes a specific job with no product name and no platform in the prompt: “what tool automatically ships code fixes from bug reports?”
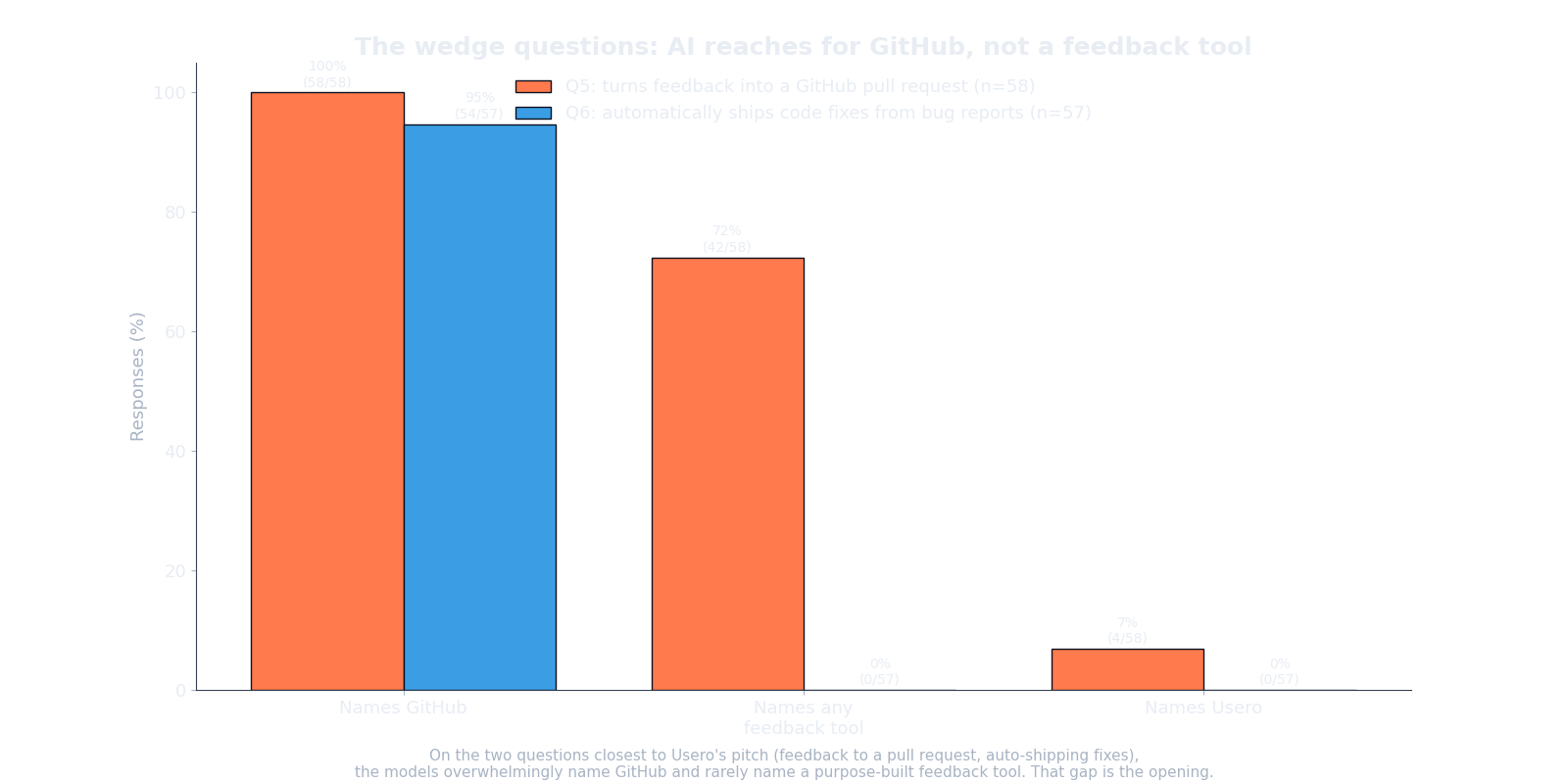
The models named GitHub in 54 of 57 answers and named zero purpose-built feedback tools. None. When the job is “do something with the feedback,” they reach for a place to put tickets, not a tool that closes the loop.
(I ran an eleventh question that named “GitHub Issues” directly. I left it out of this count, putting GitHub in the question rigs the answer.) The wedge claim rests only on the question that never mentions GitHub at all, and it still came back GitHub 54 of 57 times. When all three models default to “just use GitHub” for a real job and name no product, that gap is the cleanest opening in the dataset.
The honest disclosure
Full disclosure: I make one of these tools, Usero. It showed up in 1.4% of answers and 0% from memory, which is exactly why I ran this. The non-result is the point. The models have no memory of my product, so for me, and for every product younger than its training data, the entire game is the grounded path and the cited domains above.
That is the only time I am going to mention it.
What this actually tells you
Four things, if you are trying to get recommended by AI:
- Get cited where the models read. The grounded answer is assembled from a handful of knowable domains, and that lever moves the search-sensitive models most. I listed mine above. Go find yours and get on them. This is the one that matters.
- You do not control which model your buyer asks. The three reward different things, so the one lever that works across all of them is being present on the specific pages the grounded models actually cite, the domain list above. That is the durable bet no matter which model is on the other end.
- Pick the specific question you want to win. Vague category terms are a coin flip with a crowd, and the answer wobbles run to run. A precise phrase describing your exact job is winnable, and sometimes uncontested.
- Find the default nobody is filling. When all three reach for “just use GitHub” on a real job, that gap is yours to take before anyone names a product for it.
The raw dataset is free
I am publishing the full raw dataset: every question, every run, every tool named, every cited domain, plus the per-model breakdown. I am rerunning it quarterly to watch the answers move. If you want to see how AI decides in your category, the method is the post and the data is free.
Download the full dataset577 runs, every tool named and domain cited. JSON, free..jsonThe full dataset is right above, free to download. The script that ran the whole experiment is available too, so if you want to test your own category, you can point it at your category and run the same thing yourself.
Frequently Asked Questions
Are AI models deterministic when you ask them the same recommendation question?
No, and nobody expects them to be. The number worth having is how far they drift. Asked the same question 20 times, Gemini repeated its own most common top pick 80 percent of the time, GPT-5.5 71 percent, and Claude just 56 percent. So even the steadiest model swaps its top pick about one run in five, and Claude close to one run in two. Often it names a different product, not the same one reworded. There is no stable ranking to game. This is default-temperature sampling, exactly what a real user gets.
How do AI models decide which product to recommend?
When a model searches the live web before answering, it builds its recommendation out of whatever specific pages rank for the query, not out of brand fame. Collecting citations across hundreds of grounded answers shows the models pulled mostly from small competitor blogs, listicles, and comparison pages rather than the big review platforms. So the practical lever is getting cited on the pages the models actually read for your category, not running a louder homepage or a press release.
Which domains do AI models cite most when recommending feedback tools?
The most-cited domains were small competitor blogs and listicles like featurebase.app, quackback.io, productlift.dev, and userjot.com, alongside github.com. The seedable surfaces you can actually publish to or get listed on were github.com (62 citations), dev.to (45), reddit.com (43), medium.com (34), and producthunt.com (33). Getting into a credible roundup or a comparison page that ranks on one of those is what moves your grounded recommendation rate.
Do different AI models recommend different products for the same question?
Yes, and they start from different defaults. Gemini leans toward issue trackers, naming Jira in 61 percent of answers versus 42 percent for the other two, with some tracker appearing in 95 percent of its answers. Claude pulls from the widest surface, citing 637 distinct domains across its grounded answers versus 212 for GPT and 126 for Gemini. GPT-5.5 is the most concentrated, naming the fewest tools and settling on a small familiar set.
Does getting cited on the web change what an AI recommends?
It depends heavily on the model. When Claude switches from answering from memory to searching the live web, its top picks move an average of 16 points. GPT moves 11. Gemini barely flinches at 5, mostly recommending what it already believed. So getting cited on the live web is a lever that works hard on Claude, moderately on GPT, and almost not at all on Gemini. For a product younger than the training data, the grounded path is the only lever available.
What should you do to get recommended by AI models?
Get cited where the models read by landing on the specific blogs, listicles, and comparison pages that rank for your category. You do not control which model your buyer asks, and the three reward different things, so being present on the pages the grounded models cite is the one lever that works across all of them. Pick a precise question you can win rather than a vague category term that wobbles run to run. And look for a default nobody fills: when all three models reach for "just use GitHub" on a real job and name no product, that gap is yours to take.
Continue reading
Fix GitHub Issues Automatically: What Actually Works in 2026
Can AI fix GitHub issues automatically? An honest guide to turning a GitHub issue into a pull request with AI: Copilot coding agent, OpenHands, issue-to-PR bots, and the manual gh CLI route, where each breaks, and how to set up an issue-to-PR flow.
9 min read
Chrome Web Store Reviews: Find the Bug Hiding in Your Extension Reviews
Your Chrome extension reviews hide your worst bug under a dozen wordings, and the store dashboard never groups them. How to export and cluster Chrome Web Store reviews by theme, plus the tool that imports them with just your extension ID and turns the recurring bug into a GitHub PR.
6 min read
Feedback Inbox: One Place for Every Channel (and Why It Matters)
Your feedback is scattered across Slack, email, reviews, GitHub, and a widget, and nothing counts across them. What a real feedback inbox does that a prettier list does not, how to set one up that ranks what recurs, and the tool that turns an inbox item into a GitHub PR.
7 min read
Build a feedback loop your team actually uses
Usero collects, clusters, and turns user feedback into shipped fixes.
Get started free